
The Best AI Is the One You Trust
Cape is an Enterprise Al platform that you can run anywhere, optimized for both the security and privacy of your data.





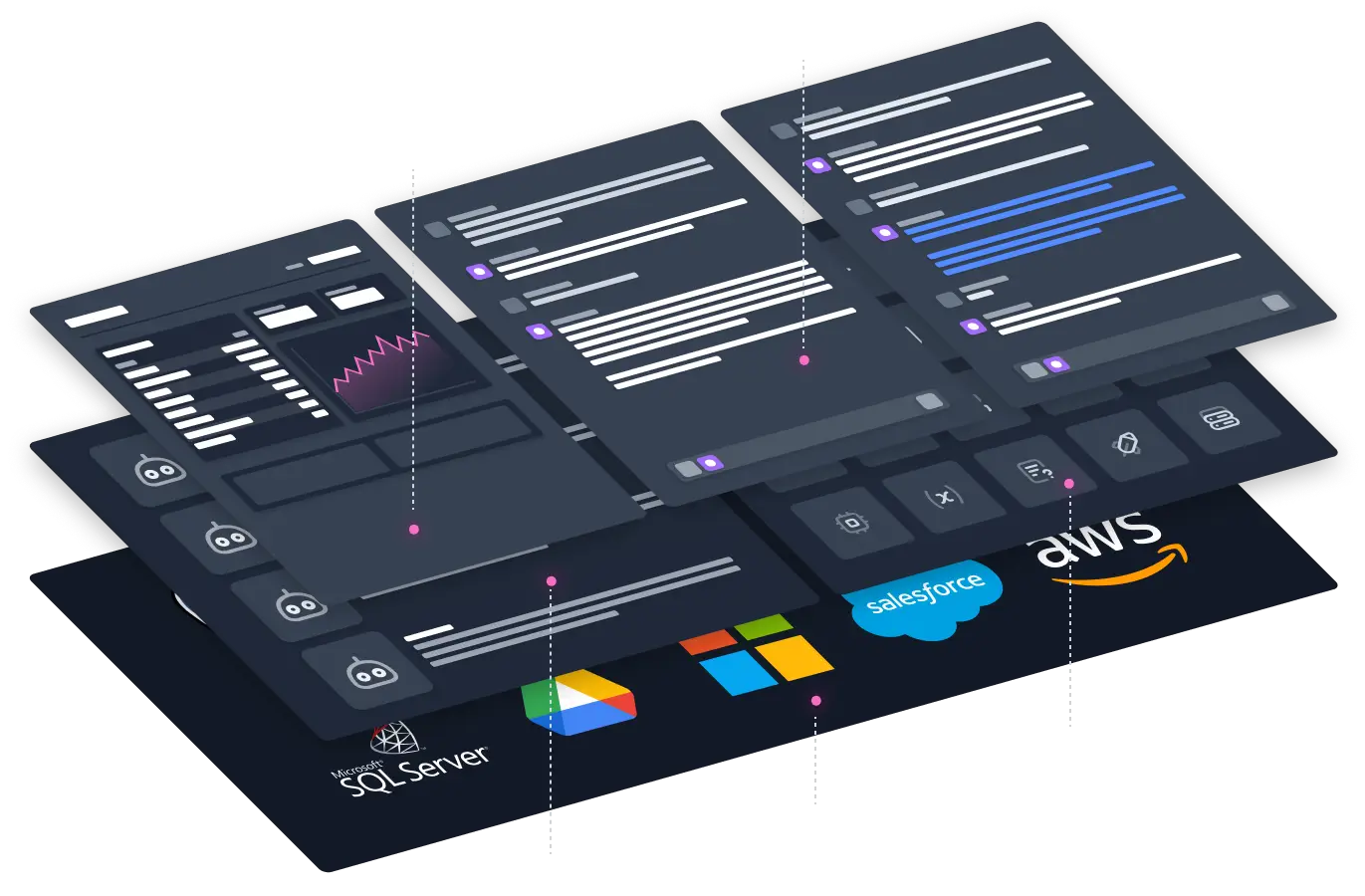
Privacy by Default
Your Own AI at the Heart of the Data
CapeChat
CapeChat is an intuitive chat interface that enables easy use of multiple public and private LLMs.
CapeAPI
The CapeAPI offers a developer-friendly API including an integrated vector database and proprietary NER model for the redaction of confidential information.
Total Redactions
28198128
Data Connectors
Cape Data Connectors allow you to work with all of your data. Seamlessly integrate data across all of your sources to automate any workflow you have.
Workflows
LLM-powered workflows to improve time to value from weeks to minutes.
This data was generated with the following SQL:
SELECT TOP 5 [Customer Key], [Current Balance] FROM [dbo].[v_ods_Active_Customer_Dim]ORDER BY [Current Balance] ASCActions
Save and re-run your most commonly used actions as snippets.
- Email users for department
SELECT users.*
FROM users
JOIN departments ON users.department_id = departments.id WHERE departments.name = 'Engineering&aspo;; - Bias?
Check this article for bias - Punchier
Rewrite this to be punchier
Trusted by 1000's of users to protect the privacy of data while using AI
Cape has enabled us to rapidly build GPT-4 powered applications while maintaining the privacy and security of our customer's confidential information.
By partnering with Cape Privacy, we have not only simplified the process of securing our customers' data and processing pipelines tenfold, but also raised the bar for data security beyond the current industry standard.
Cape has provided a valuable technology platform for us to leverage the power of LLMs while maintaining the privacy of confidential data. By doing so, Lokker has been able to enhance our privacy solution to offer our customers generative AI features and capabilities easily and securely.
CapeChat provided us with an intuitive and robust solution to secure our data while using AI. This allowed us to substantially accelerate adoption across the entire team.
CapeChat was featured as a top Product of the Week on Product Hunt.
Backed by world class investors






